The goal of this Milestone is to implement and a sitemap generation engine and deploy it with SlapOS. SlapOS is a general purpose operating system usable on distributed POSIX infrastructures (Linux, xBSD) to provide and manage software services without the need for virtualization.
This work provide an opensource app for crawling any website and generate sitemap without limitation as we can see with online crawler solutions. The main purpose is to use crawled sitemap into Mynij.
Sitemap generator
Mynij-crawler is a NodeJS application that was developed for crawling site, it uses simplecrawler API to fetch website content and build sitemap XML file. Source code can be found here: https://lab.nexedi.com/Mynij/mynij-crawler.
To run the crawler with NodeJS:
$ git clone https://lab.nexedi.com/Mynij/mynij-crawler.git
$ cd mynij-crawler && npm install
# crawl nexedi.com
$ nodejs crawler.js -l https://nexedi.com -d 3 -f nexedi.xml
crawled 515 urls
$ cat nexedi.xml
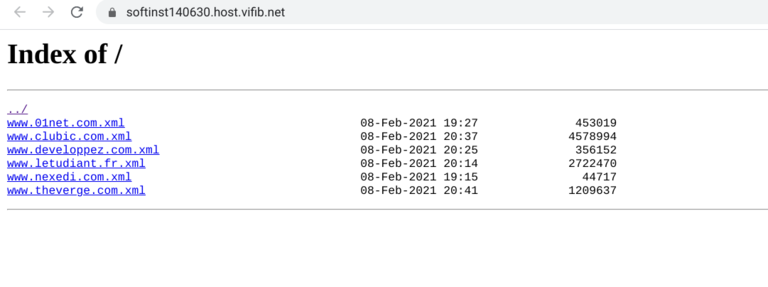
The file nexedi.xml is the sitemap generated, this file can be placed in a http server and used to configure a new Mynij index source.
Slapos Integration
Mynij-crawler deployment with Slapos expose the app as a service, with an http server for downloading sitemap files. The deployment is automatized through Slapos recipes, and we just have to request a new crawler service with the list of websites to generate sitemap as service parameter.
This service deploy a cron job which build sitemap in backgound and expose the generated file to http server. Another service parameter can define the re-crawl periodicity, this mean after a specified amount of days, the sitemap will be updated automatically by the cron (useful to get new published links in the website).
Jscrawler for slapos was released with slapos 1.0.177, and can be deployed as a service in Vifib cloud. To learn how to request an instance in Vifib, please check this documentation: https://slapos.nexedi.com/slapos-HowTo.Instantiate.Webrunner.
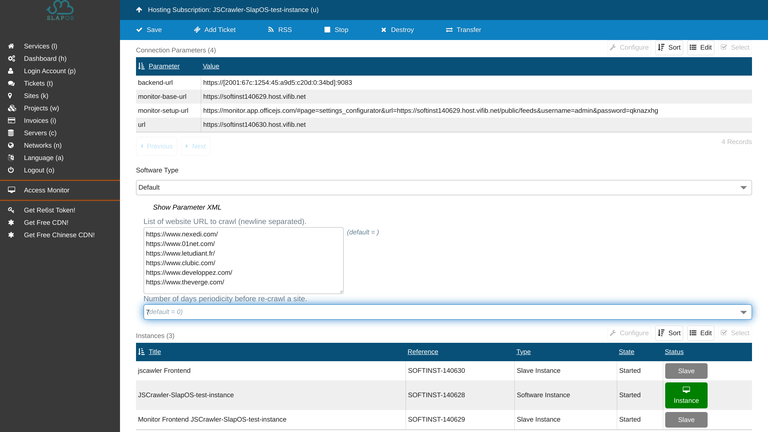
Published parameters of the service are:
- url: URL for http file server, this link can be used to download sitemap, for example,
http://softinstXXX.host.vifib.net/www.nexedi.com.xml can be used in Mynij to add https://www.nexedi.com source.
- monitor-setup-url: Monitoring URL used to check the health of the instance in SlapOS.
Custom deployment with SlapOS
Crawler software release can also be deployed in a personal server (deployment below was tested on Ubuntu18.04 and debian), a playbook made with Ansible install Slapos using only a single line installer.
$ sudo su
# wget https://deploy.erp5.net/slapos-standalone && bash slapos-standalone
Request the crawler software release
# slapos supply https://lab.nexedi.com/nexedi/slapos/raw/1.0.177/software/jscrawler/software.cfg local_computer
# tail -f /opt/slapos/log/slapos-node-software.log
The software release will be downloaded from slapos cache and stored in your local slapos installation. Wen finished, you can now deploy the instance.
# cat << EOF > request-jscrawler.py
# update this variable to add more urls
crawl_urls = """https://www.nexedi.com/
https://www.theverge.com/
"""
parameter_dict = {
'urls': crawl_urls,
'crawl-periodicity': 7
}
request('https://lab.nexedi.com/nexedi/slapos/raw/1.0.177/software/jscrawler/software.cfg',
'instance-of-jscrawler',
filter_kw={'computer_guid': 'local_computer'},
partition_parameter_kw={
'_': json.dumps(parameter_dict, sort_keys=True, indent=2),
}
).getConnectionParameterDict()
EOF
Request instance is done with this command:
# cat request-jscrawler.py | slapos console
This command can be re-run to update parameters or to get instance connection parameters. To add more url to the crawler, simply update "crawl_urls" variable in request-jscrawler.py and call request command again.
To check the status of running services, 'slapos node status' command can be used.
# slapos node status
slappart0:bootstrap-monitor EXITED Feb 11 07:49 PM
slappart0:certificate_authority-4aac66f1fdf55f4caf33402f74c27f48-on-watch RUNNING pid 22100, uptime 16:42:24
slappart0:crond-4aac66f1fdf55f4caf33402f74c27f48-on-watch RUNNING pid 22104, uptime 16:42:24
slappart0:http-server-on-watch RUNNING pid 22101, uptime 16:42:24
slappart0:monitor-httpd-4aac66f1fdf55f4caf33402f74c27f48-on-watch RUNNING pid 22099, uptime 16:42:24
slappart0:monitor-httpd-graceful EXITED Feb 11 07:49 PM
slapproxy RUNNING pid 1696, uptime 1 day, 1:04:45
watchdog RUNNING pid 1693, uptime 1 day, 1:04:45
After runing request intance command again, connection parameters bellow are showed
# cat request-jscrawler.py | slapos console
{'_': '{"url": "https://[fd46::b83d]:9083", "monitor-setup-url": "https://monitor.app.officejs.com/#page=settings_configurator&url=https://[fd46::b83d]:8196/public/feeds&username=admin&password=smikdrlx", "monitor-base-url": "https://[fd46::b83d]:8196"}'}
It's now possible to open url https://[fd46::b83d]:9083 in a browser to check crawled sitemaps when they are finished.
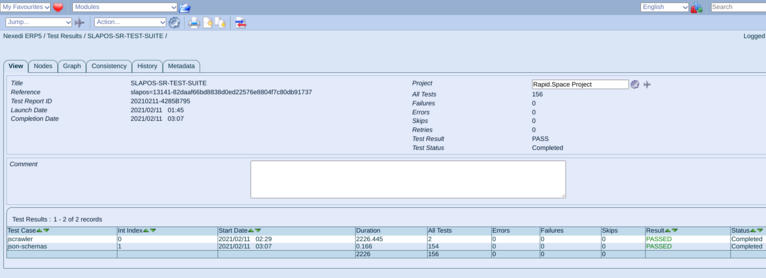
Sitemap generator software release test suite
The Jscrawler Software Release test suite run on every commit on slapos to ensure that the latest code is working as expected. Each test, build the Software Release from scratch, create instances with various parameters and assert that instance is functional with the provided parameters.